I needed to setup another WordPress for something else, and I host it on a server with no https. However of course it’s fronted by a proxy with https. And WordPress embeddeds the http into the stream, and changing that with redirects causes it to ping pong like crazy.
So this is by no means the best fix, it is *A* fix. For me. YMMV.
I had to add this into the site config from apache
<Directory /var/www/mynewsite.org/>
Options Indexes FollowSymLinks MultiViews
AllowOverride all
Order allow,deny
allow from all
Require all granted
</Directory>And does that work? no it sets up mod_rewrite (you did a2enamod it right?! RIGHT?!)
RewriteEngine on
Header always set Content-Security-Policy: upgrade-insecure-requests
RewriteRule ^$ /wordpress [L]
So the big thing here is updating the header. I had to search a bit to find that part, so yeah that was needed. The other part is that wordpress really wants to be in /wordpress not in the root, so a simple RewriteRule will put that in it’s place.
Good Grief.
I should explain my hosting situation more. I’ve been forced into some kind of nomadic situation, and thanks to some weird issue on Azure’s WordPress container thing my site ate itself. Like it literally destroyed the files. I had backups of course, and well either being evicted from a data centre because of the Windows CE Nethack scandal, or having hosting companies either go under with no warning, or drop me for being far too much traffic than they signed up for, I’d taken to not only owning my data but hosting it all myself.
I do enjoy the ‘nomad’ aspect of it all, but it’s a little crazy. I like to think of this as portable stealth hosting as I can blend into user traffic, and I can physically take my data with me. Of course, I have backups as well!
So to describe the setup I guess i need a fine MS Paint style drawing!
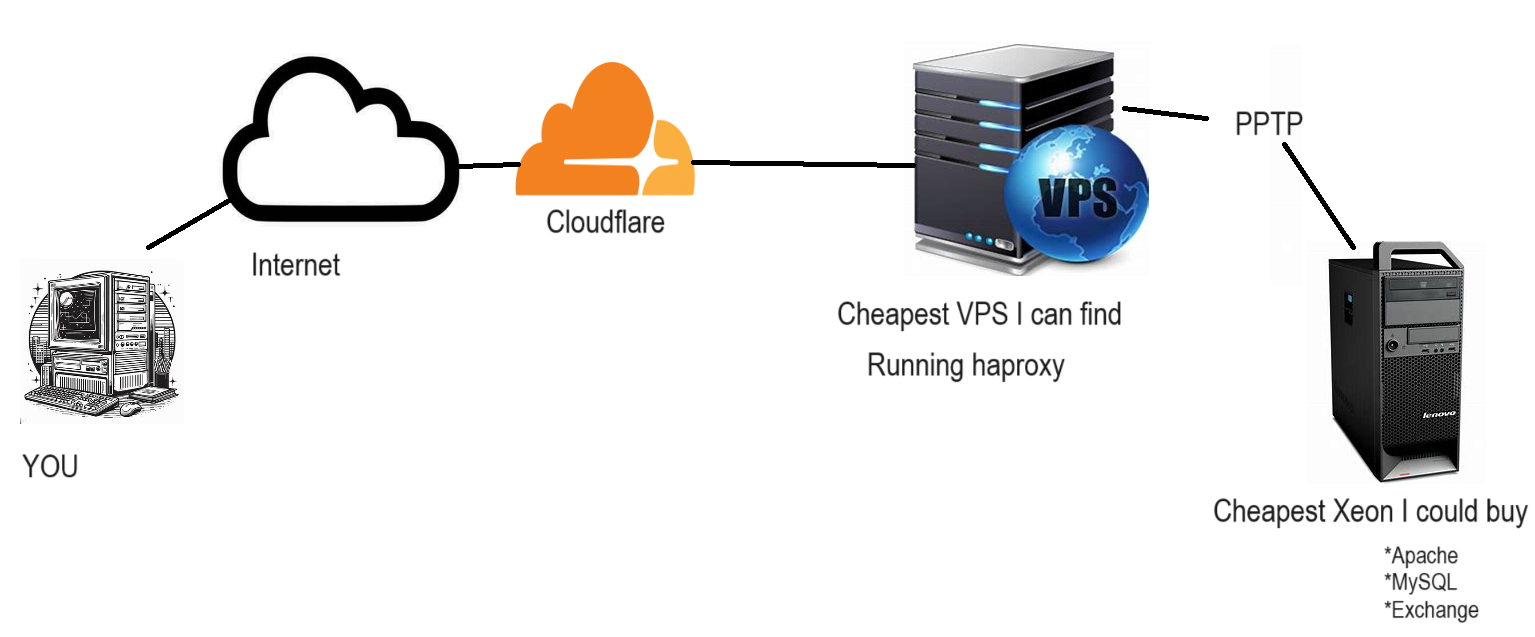
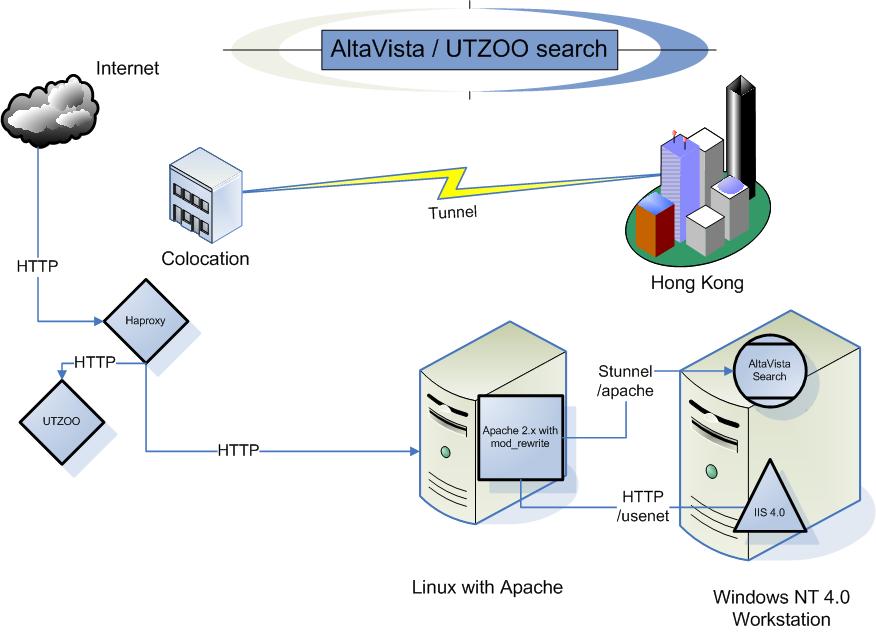
I have been using this kind of setup to some degree going back to when I setup the utzoo search engine back in 2017. I’d only expanded on it to host everything now. Working backwards I need to blend into residential traffic, so I need a typical 90’s like office vpn, which means PPTP. So going on lowendbox, I get some cheap VPS, install haproxy and PPTP server onto that. This way I’m basically renting out a static IP address for less than a Starbucks, but it let’s me have the freedom to move around and just look like user traffic, as the PPTP connection is bi-directional.
On the VPS I use a haproxy much like this:
bind *:443 ssl crt /etc/haproxy/haproxy.pem
redirect scheme https code 301 if !{ ssl_fc }
mode http
acl cloudflare src 173.245.48.0/20 103.21.244.0/22 103.22.200.0/22 103.31.4.0/22 141.101.64.0/18 108.162.192.0/18 190.93.240.0/20 188.114.96.0/20 197.234.240.0/22 198.41.128.0/17 162.158.0.0/15 104.16.0.0/13 104.24.0.0/14 172.64.0.0/13 131.0.72.0/22
tcp-request content accept if cloudflare
tcp-request content reject
acl host_utzoo hdr(host) -i utzoo.superglobalmegacorp.com
acl host_utzoo hdr(host) -i altavista.superglobalmegacorp.com
acl super_virt hdr(host) -i virtuallyfun.superglobalmegacorp.com
acl host_blog hdr(host) -i virtuallyfun.com
acl host_blog hdr(host) -i unix.superglobalmegacorp.com
acl host_bow hdr(host) -i bow.superglobalmegacorp.com
acl host_blog hdr(host) -i oldlinux.superglobalmegacorp.com
acl host_blog hdr(host) -i macmint.superglobalmegacorp.com
acl host_blog hdr(host) -i tuhs.superglobalmegacorp.com
acl host_nt31 hdr(host) -i winnt31.superglobalmegacorp.com
acl host_blog hdr(host) -i superglobalmegacorp.com
acl blog_path path_beg -i /wordpress
acl blog hdr(host) -i virtuallyfun.com
redirect prefix https://virtuallyfun.com code 301 if { hdr(host) -i virtuallyfun.superglobalmegacorp.com }
http-request set-uri %[path,regsub(/wordpress/,/)] if blog_path blog
redirect code 301 location https://virtuallyfun.com/ if blog_path blog
use_backend utzoo if host_utzoo
use_backend lenovo if host_blog
use_backend nt31 if host_nt31
use_backend bow if host_bow
backend utzoo
server zoo1 192.168.23.10:8080
backend lenovo
server blog1 192.168.23.10:80
backend bow
server bow1 192.168.23.10:8888
backend nt31
server apache 192.168.23.5:80This way I can use various backend servers to split up various domains on the same port. Since cloudflare fronts I don’t need any weird SSL certificate with combination domains. I also get to sneak in a redirect for the old virtuallyfun.superglobalmegacorp.com, as google had a major fit about me not having it at the top level domain. The Windows NT 3.1 server is a Qemu virtual machine running on the VPS. It just has a static page so there wasn’t much point being all that sophisticated.
I then setup a Cloudflare account, and then point my domain directly to the VPS. This also let’s me grab a certificate from Cloudflare to load onto the VPS to encrypt the conversation from them to my VPS, just as the PPTP connection is also encrypted. Another advantage of PPTP over say IPsec is that older OSs like Windows NT 4.0 support it. Not to mention with tunnels being left up so incredibly long, once again I want to blend in as user traffic, and IPsec or OpenVPN just draws too much attention. It sure did in China, and sadly that’s the model I fully expect more and more of the world to be following.

The other advantage of Cloudflare is that they do some aggressive caching which makes hosting on a residential connection viable. In this case over the last 30 days I’ve only had to ‘upload’ 41 of the 158GB of traffic.
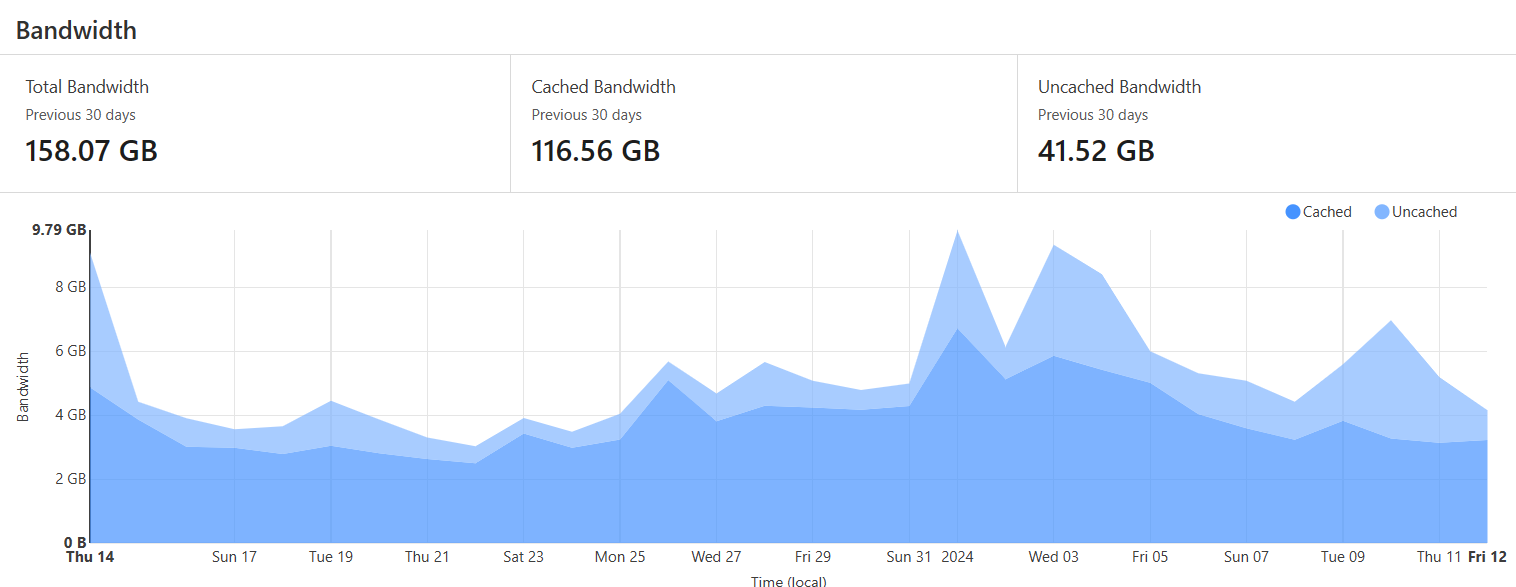
If something gets popular this can make all the difference! Again, it’s key to being stealthy.
In the same way it also allows me to host my own Exchange, or any other weird application. Which then takes me to the Apache config. I have Windows 10 on the Lenovo, and loaded up WSLv1 so I could have Windows natively integrate with the filesystem. I also like that it’s got such low overhead as WSLv1 is just a subsystem, unlike v2 being a lightweight VM, like shades of Win/OS2 back in the day. My setup takes a big page from running SWGEMU on WSLv1, where I use the Win64 version of MariaDB, and the Apache/PHP is in a Linux Ubuntu distro. The other advantage here is that as my Lenovo PPTP’s into the VPS, the Apache will by default listen on port 80. Which then leads to the whole needing to set security on the headers to allow the http to become a seamless https.
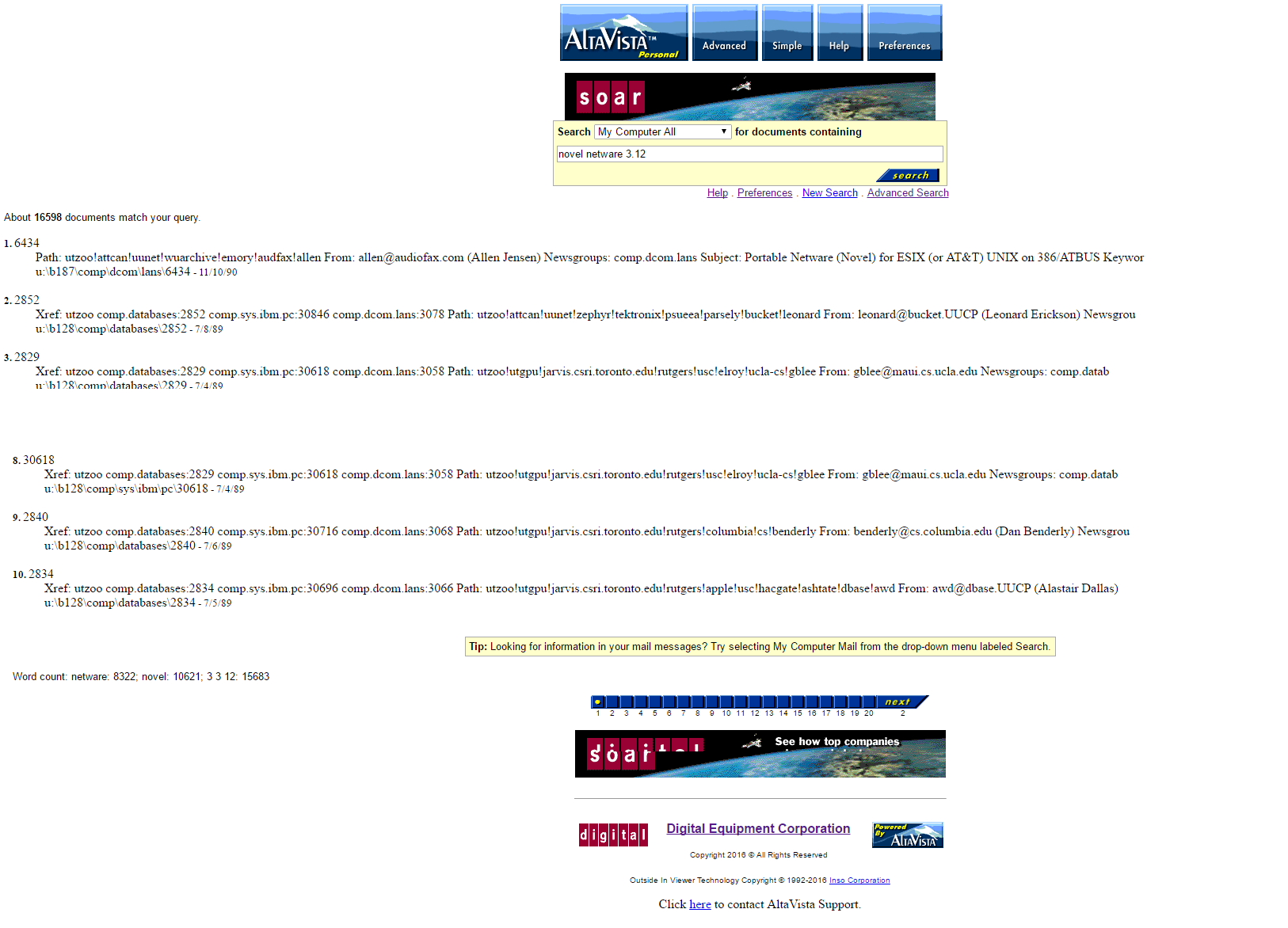
I also can have multiple things listening on different ports, just as I use haproxy again locally to split out the utzoo site onto the old Apache server with all the re-write rules, and then finally to the Windows NT 4.0 workstation with the Altavista Personal desktop search.
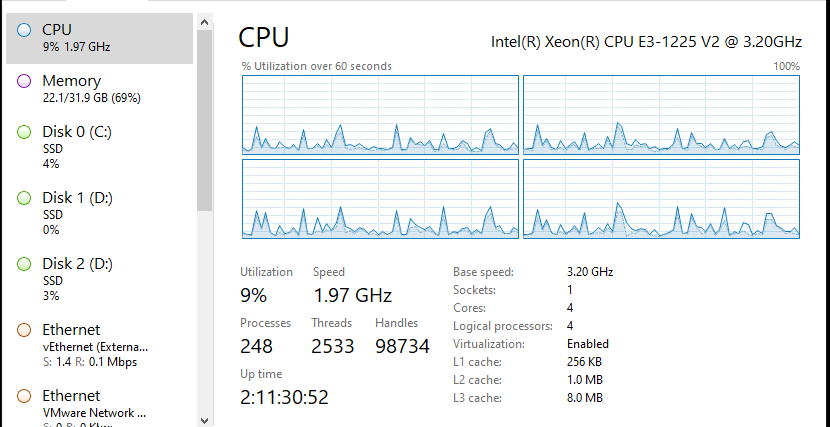
The overall performance on this low end Xeon E3-1225 v2 is quite acceptable.
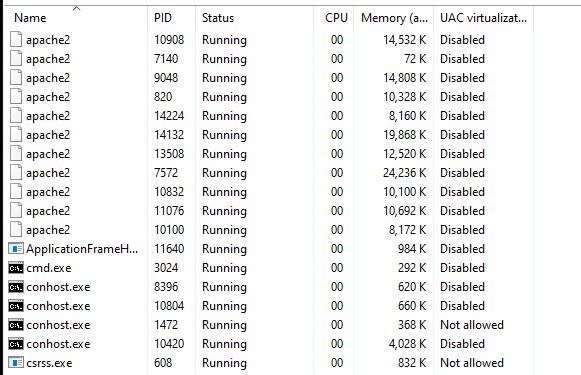
As I had mentioned WSLv1 being a subsystem means that the processes are transparent so task-manager can immediately show yo what is going on. The opaqueness of Virtual Machines just adds to the time to identify any issues.
And all it takes is a scheduled task to dump the MariaDB, and run an xcopy onto my OneDrive, and now I’ve got a cloud backup. No plugins needed, no scripts that will break as cloud API’s are forever being depreciated and changing. Very nice!
I do like the flexibility of this being a somewhat simple setup. Not to mention being able to have more than one WSL container for various applications, being able to go so far as to break my Apache setup into multiple instances, all being ‘l7 routed’ through an instance of haproxy either at home, or in the VPS is very nice.
Oh, sure I could mess with self signed certs, and trust myself but I just didn’t want to deal with the overhead of double encryption. Maybe it’s something I’ll revisit later.
Also sorry for the ads. 2024 is starting out…. interesting.